POSTS
Take That Vacation: Eliminate Alerts Dragging You Back to the Office
I authored this as part of SysAdvent, which posts one system administration-related post each day in December, ending on the 25th. You can find the original posted here: http://sysadvent.blogspot.com/2016/12/day-15-take-that-vacation-eliminate.html
–
It’s mid afternoon and you just sat down for that holiday meal with your family and friends. Your phone goes off and you look at the number. Work, again.
Before you even read the text or answer the call with the robotic voice telling you about the latest problem, you’re wondering to yourself “how long it will take?” Your relatives are only in-town for another day or two, before you have to take them to the airport. What if it goes off again later? A holiday potentially ruined.
You read the text. Maybe it’s a false alarm. Maybe it’s not. Either way you’re out of the moment–worrying about work and if things are going to break over the holidays.
Don’t Be Your Own Grinch
It’s possible to engineer yourself and environment for success.
Rome wasn’t build in a day, and neither was your current alert setup. It won’t take a day to clean up either. But you can apply two simple verification rules to each of your alerts:
- Is the alert actionable?
- Do you have to deal with the alert right now?
Take inventory of your monitoring system
Like that jumbled pile of SCSI and other ancient cables that are sitting gathering dust in your office that you should have thrown out but you’re holding on to hoping to be useful someday, your monitoring is gathering dust too. Since you made and configured the health checks, your environment has changed. Code has changed, hardware swapped, and resiliencies added–we’ve got to do a bit of spring cleaning.
You’ll need some time to be able and go through your alerts. Block out some time on your calendar so you can work without interruption. Get away from your desk to avoid surprise visitors. Get someone to cover the alerts for an hour or two, so you don’t get distracted by any more false alarms.
Many monitoring systems have reporting tools to tell you what the most frequent events are. This report is a great starting point for where to start cleaning things up. If your monitoring system doesn’t have a prebuilt report or convenient export to CSV, which you could then manipulate with Excel’s pivot tables, it may be possible to do a bit of scripting of the monitoring system’s log file. Your favorite scripting language should be able to pull out all of the log lines relating to a notification being sent and give you some data that’s workable.
Is learning a scripting language one of your New Year’s resolutions, or on that someday list after the alerts stop nagging you every 15 minutes? Your email inbox is probably the next best source of the alerts you’ve been getting. After all, your most recent alerts are the ones most likely to bother you on your next vacation.
If you’ve been deleting the incoming notifications or really feel like doing a top to bottom cleaning of your monitoring system, you can just go down the list of checks.
Alerts need to be actionable
Once you’ve determined how you want to attack the problem, it’s time to apply the first rule: “Is the alert actionable?”
Write down all of the steps required to fix the issue in complete detail. If your first reaction is “ignore”, it’s not actionable. If the first step is “wait”, “hope”, or “pray”, followed by “for everything to return to normal”, it’s not actionable. Delete the check. Checks that aren’t there can’t possibly notify you, and if checks are inactionable they’re just noise for when problems really do exist. If you still feel strongly that this check is doing something important even if it’s not actionable, make a note of the check and we’ll cover how to address them shortly.
You should have written instructions that look something like this:
- Connect to the server identified by alert
- Run X command to verify the problem and determine the cause
- If <A>, do this
- If <B>, do this
- Else, do this
- Check the monitoring dashboard to make sure it’s resolved
Write out everything. Even if it’s just “Call $VENDOR at 1-800… and open a support case”, that’s still reinforcing the fact that this is actionable.
The reason you write all the steps down is because you’ve just documented the fix, and it’s the beginning of what could become a runbook. Boring, right? But documentation has got to be done and you’re thinking about the alert anyway.
Whether you put the documentation in a wiki, a knowledge base, or in the alert notification itself is entirely up to you, your company’s designated systems of record, and willingness to keep the instructions up to date. But you’ve just saved yourself from having to remember how to fix the issue, whether it’s tomorrow afternoon, in the middle of the night, or on your next vacation. You can also use the documentation to train other employees so you’re not the only person who knows how to fix the issue. Not being the only person who knows how to solve the issue is critical in your ability to take an uninterrupted vacation.
Now sometimes alerts are used to notify you of events that happened, and you really want to know about the event, but the notification you’re getting isn’t an actionable alert. You’re basically using your inbox as a system of record. That’s fine, not everyone has the ELK stack running or a Splunk subscription to forward these things to. But these events need to go somewhere that’s not your Inbox so they stop causing you stress. Set up a email list or shared mailbox to send these events to, or use some smart email filters. This way you can still get the events but they’re not front and center in your inbox every time you open your mail. You’ll get a better understanding of when things are broken, since the signal to noise ratio in your inbox will be higher.
Do you need to deal with the alert right now?
This question is phrased like one of those True or False problems your teachers gave you in elementary and middle school. Both parts need to be True for the entire statement to be True. There’s two critical parts:
Do you need to deal with this alert right now
You: Are you the right person to deal with this alert? If you’re front line support responsible for escalating to the right person, this is going to be True. If you’re on a small or single-person team, this is going to be True. However, if you’re in an organization where there’s a defined separation of duties and these alerts are going to the wrong place, then that alert needs to be corrected. Perhaps this is just a case of an overzealous email list – all IT rather than network or desktop or server teams. Update the alert to go to the right people. This isn’t just helping your workload, but also theirs, since misrouted alerts cost precious time when critical systems are down.
Right now: There’s two options if your health check doesn’t need to be dealt with right this moment. The first is to change the thresholds so the alert doesn’t fire until it absolutely requires the action. The second option is to change your monitoring system so this event goes to a lower priority notification channel like chat or email, rather than contacting your pager or mobile phone. This change may require adjusting the thresholds down even further than you’d think, so you get sufficient advanced notice–letting you wait until after vacation to handle the issue.
Improving the remaining alerts
After going through your alerts you should be left with only the alerts that mean something. They’re letting you know of bad things happening, and they’re at least somewhat actionable. Your phone may still be noisy with the constant chime of incoming messages though.
(If you’re holding on to any inactionable alerts, these are things you can do to help make the alert more actionable.)
Make sure checks are covering the right things
A lot of times people suffer through ill-fitting alerts because it’s the easiest one to setup. CPU is probably the biggest offender. It’s easy enough to put a threshold for 95% CPU and call that “bad”.
But what does that 95% CPU measure? Chef or Puppet runs. Cron jobs. Backups. Disk deduplication. There are a lot of intensive operations that may pop up only periodically and then vanish, but it’s enough to start tripping monitors.
What are you really trying to measure for? Most of the time it’s responsiveness. Can you instrument for this true metric? Think database query times or page load times. These values can be found in log files, or instrumented in your application and then alerted on.
If you can’t get the right things measured, can you at least reduce the impact of everything else that will result in the same symptoms? So for those Chef or Puppet runs, change the process priority so it doesn’t make as much of an impact. No one cares if non-critical tasks take 30-45 more seconds to complete if that means your website is still fast. You might also have to provision more resources to reduce the impact. Spread the load out over more machines so any single machine is getting fewer requests than it was before and therefore less likely to hit the notification threshold.
Another example is RAID arrays. Most arrays are setup such that they can lose at least one disk without issue. In a more built-out setup, you may have some hot spares so the array will automatically repair itself if a disk fails. Instead of paging on disk failure, consider only sending an email for the failed disk and then send a pager alert when you run out of hot spares. This will ensure you know about all failed disks, but only need to take action when the system can’t fix its own issue.
Think automation
Go back to the documentation you wrote earlier on how to fix the problem causing the alert. Does it seem like something that could be automated simply?
Maybe when your disk fills up you go hunting for the largest file and delete that, or you force a log rotation. When your process crashes you try restarting it. When your webservers have too many concurrent users you spin up another host from your cloud provider.
These are all actions that can be taken programmatically, and possibly worked into your monitoring system. Attempt to resolve the issue automatically, and if the issue cannot be resolved, or if the problem is reoccurring then notify. Now you know the computer has taken the most common resolution steps, and your advanced troubleshooting knowledge is required.
Generally automation works out in your favor, if you assume most off-hours alerts are going to take you at least 30 minutes to start up your computer, log in, verify the issue, and then resolve it.
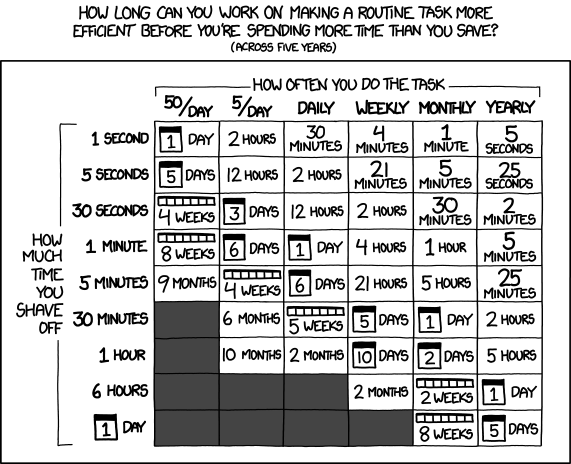
XKCD 1205: How long you can work on making a task more efficient before there's no ROI
Be careful with your automation, however. There are many pitfalls that lie down this path, particularly with destructive resolutions like restarts and deletions. Heed this sage advice:
> > To make error is human. To propagate error to all server in automatic way is [#devops](https://twitter.com/hashtag/devops?src=hash). > > — DevOps Borat (@DEVOPS_BORAT) [February 26, 2011](https://twitter.com/DEVOPS_BORAT/status/41587168870797312)
Consider just some of the following questions as you design your solution:
- What happens if the state keeps changing between bad and good, a condition known as flapping?
- When don’t you want this fix to automatically take place?
- What happens if the fix fails mid-step?
- Will the automatic resolution conflict with any intentional work, like downtimes, upgrades, or patching?
Start off cautiously and log what actions you would have taken. Then once you’re confident the automation always does the right thing, then you take off the training wheels.
Reinforce the weak points
Sometimes your environment just needs a bit of shoring up. There are weak points and single points of failure due to natural growth.
Maybe the application is brittle and doesn’t try re-establishing connections after a network outage. This is a problem you can raise with the application team for them to fix.
Maybe the weak point is old-fashioned capacity management. Add some more capacity because the business has outgrown what it was originally designed for. You’re out of disk or network or processing power to handle how things are today.
Maybe you need to consider higher availability solutions. Being able to transition seamlessly to a backup would mean your notification changes from “EVERYTHING IS DOWN!” to “Please address this by close of business today”.
Unfortunately these fixes involve time and money, which is why you may be hesitant to skip this section when it comes time to implementing what you’ve read here. It doesn’t have to be this way, you just have to demonstrate the value of having things improved. In other words, return on investment, or ROI.
If the impacted systems are revenue facing, where an outage means the company isn’t making money, the cost of downtime is fairly easy to calculate. The revenue you should have made minus the revenue you actually made will tell you how much that outage cost. This can be normalized to a per-hour basis so you can work with smaller outages like 5-10 minutes.
If your impacted systems are internal facing, where an outage means employees are annoyed or unable to do their work, you can ballpark a cost of the downtime using average employee cost per hour times the number of impacted employees.
Where do you get these costs? Generally you can get this from your manager, as they may already deal with these figures, or accounting.
All this napkin math (it’s impossible to be completely accurate for all situations) is simply to get upper management in the ballpark of missed opportunities and appropriately judge the cost of solutions against it. A $50,000 solution sounds expensive, but when it can save $75,000 in losses it starts to look more appealing.
The case for reduced support hours
Not everything needs to be running on a 24⁄7 basis. When have you made a special trip into work after hours to replace the paper or ink in the office printer? Likewise, not everything in the company needs to be supported around the clock. Sometimes there are workarounds available to the impacted employees, or they can perform another task first while the system is down.
You’ll need to work with the impacted groups, but it is possible to reduce the level of support from 24⁄7 to normal business hours. You’ll respond as normal to problems, but only during the designated times. The business may need more or around-the-clock coverage during peak season or “crunch time”, but your inbox will be better off the remainder of the year.
Remember, there’s a reason that your vendors charge more for faster support. The dollar cost for you or your organization covering everything 24⁄7 may not be immediately visible to your business in terms of wages, but it’s paid by employees not getting enough rest or impacting their work-life balance.
Don’t steal your own holidays
This whole process is as gradual or extreme as you’d like. But I encourage you to at least start working on your alerts today, and keep it in mind as you add new alerts. There will be setbacks, as new systems come online and existing systems change, but overall you’ll see a reduction in alerts over time.
Consider it this way: your monitoring system is a constant reminder of the work you did or did not put into it. Not putting anything at all into monitoring will result in you never knowing if systems are down. Not putting enough work into the system can result in frequent alerts, dragging you back to the office after hours.
Monitoring systems are a constant battle as your environment changes, but by keeping these strategies in mind you can help the future you enjoy the holidays without worrying about unstable systems and unnecessary alerts.
–
This post was written by Cody Wilbourn and edited by Matt Jones (@CaffeinatedEng) for SysAdvent December 15, 2016