POSTS
Tiered Storage With Elasticsearch
Elasticsearch allows you to setup heterogeneous clusters, that is, nodes with different configurations within the same cluster. Elastic (the company) refers to this architecture as “Hot-Warm”, but it’s called tiered storage if you come from a storage background.
The canonical example is that you have a bunch of data you want to keep online and able to query, but it becomes less relevant over time. You want to cut costs, so you have your “Hot” data that is written and/or read frequently, most likely on SSD, and then “Warm” data accessed less frequently on less expensive nodes, most likely on spinning disks. But it doesn’t end there, this architecture can be used and extended in different ways
What Data to Tier?
Tiered data works best when you can definitively point to a time when the data isn’t used as frequently, and that old data may still need to be combined with newer data in a query.
This could be on a time-series basis, like with ELK (Elasticsearch Logstash and Kibana) for log processing. You’ll stream logs continuously, but if you save the data into a time-based index, you can say definitively that after midnight you won’t write any more logs to that day. Now you can optimize the current day for writes, and historical data for reads.
This could also be on a project basis. If you’re using Elasticsearch for a manufacturing project, when you move on to version 2.0, the data for version 1.0 can be relegated to lesser cost storage since engineers won’t be looking at it frequently.
But there’s an odd case that I don’t think anyone has addressed before in that you could use Elasticsearch’s segregation capabilities to shove two distinct datasets into a single cluster. Elasticsearch has two primary use cases, the search case – indexing and searching text, and the analytics case – aggregating data for analysis using something like Kibana. Depending on your data, these use cases may require different setting tweaks, which could coexist on the same cluster on separate nodes.
While this is probably not a hyper-optimized solution and may not get you the best performance for all queries, as some settings are shared at the cluster level, it simplifies operational management in only having on one cluster on one shared version with one endpoint for clients to use. The version in particular is a big one – since the elasticsearch-py driver I’m using only allows one client protocol version per process, I can’t split queries between 1.7 and 5.x clusters. This means I have to upgrade multiple clusters the application queries from in lockstep. If you’re a small shop this may be a solution to needing yet more master nodes to manage another few nodes worth of data and simplify version upgrades.
Allocating Data
Elasticsearch allows for arbitrary host identifier strings, of the format node.. The example Elastic gives is node.box_type=hot, but there’s also documentation with node.tag=value1. So long as you don’t clobber anything else that has a meaning, like node.name, almost anything goes.
Each identifier can only be specified once, that is node.tag: value1; node.tag: value2 in your yaml would result only in value2 being saved. If you want both values, you would need two different attributes, like node.tag1: value1 and node.tag2: value2. We’ll see why this you want to avoid this in a second.
You move data around by setting routing allocation. You can include, exclude, and require certain tags, like so
curl -XPUT 'localhost:9200/myindex/_settings' -d {
'index.routing.allocation.include.tag': 'value1,value2',
'index.routing.allocation.exclude._name': 'host1,host2',
'index.routing.allocation.require.disk_type': 'ssd'
}So with this command, I would move the index named “myindex” on to any host that had node.disk_type: ssd and either node.tag: value1 or node.tag: value2, except if they were node.name: host1 or node.name: host2. So if you proliferated your tagging, your allocation statements become very complex, and very easy to end up where data can’t be allocated anywhere. You likely won’t find this out until a shard goes missing and the replica can’t be re-created any other node because it fails all of the evaluation rules.
Luckily, tiering of data can be almost exclusively done with a single unique attribute and the index.routing.allocation.require.{attribute} directive. You’ll occasionally need the exclude._name to evict data from a host in order to do maintenance on it. If you’re getting more complex than a single attribute, you’re sub-tiering and should think about just bringing that up to the top level to reduce complexity.
Naming things is a hard problem, so think about your needs now in addition to down the road. While you might start off with “hot” and “warm” to describe your data, you quickly run out of modifiers. Hot, warm, cold come easily, but if you had to expand later you’d end up with something like scorching, tepid, and lukewarm.
Data can be tiered based on numbers - 0, 1, 2, 3, 4 are known in the storage world for performance. Higher numbers denote slower storage, so 0 is your fastest. You don’t have to start off with the first 0 and 1, you could pick 1 and 3 allowing you to slot in more node classifications later. You can also go nonstandard and pick any number–there’s always more. This route needs more documentation for anyone else coming in to understand.
System Architecture
Now that you’ve figured out your tagging scheme, how do you set up your systems?
Elastic recommends 3 dedicated master nodes for larger clusters, which this probably is since you’re splitting out your data within the cluster. A master node manages cluster state and participates in elections. They’re designated by node.master: true and node.data: false in the configuration.
You then need enough nodes in each tier to handle all of the copies of data you need. If you have "number_of_replicas": 1 in your index configuration, you will have a primary and replica (2 copies) of your data. This means needing at least 2 nodes, since a replica won’t be stored with its primary.
So within a cluster, you have master nodes talking with all the nodes to coordinate state, with the master nodes electing one another as primary. Within a tier, you will only have queries for the data existing on that tier. Assuming your tiers are mutually exclusive, e.g. “hot” tier won’t have anything other than “hot” data, you can think of this as a cluster within a cluster, just sharing some state coordination.
The problem with this setup is that the incoming queries may not respect your tiering boundaries, particularly if you allow the Elasticsearch driver to sniff and connect to hosts automatically. If you send a query looking for “hot” data to a node designated for “warm”, that “warm” node has to play director for the fetch and aggregation sequence of that query.
To avoid this, you can have different sections of code connect to different nodes depending on what they’re querying, but that requires too much effort and complexity in most cases. So instead, you can use what Elasticsearch refers to as “client” nodes. These nodes take incoming queries and route to the correct nodes, then perform the aggregation of results. They’re designated by node.master: false and node.data: false. What happens if you turn off master eligibility and data storage? You’re left with a node that pretty much only babbles HTTP and Elasticsearch Thrift protocol.
These client nodes are the perfect endpoint to use as a single point of entry into a heterogeneous cluster. You can provide as many client hosts as you need for redundancy/geo-location. Depending on your security model, you could restrict database access to only these client nodes, such as with AWS EC2 security groups.
A client node exclusively for data exploration is helpful in avoiding cascading failures. Elasticsearch timeout doesn’t actually stop the query when the timeout is reached, just closes the connection to whoever sent the query. So while your applications may have tightly vetted and logged queries, one-off queries run by a human on your data could trip Elasticsearch circuit breakers or exceed JVM heap limitations by aggregating high cardinality data. Let users crash this one client rather than the application, which will be using a separate client.
Your End State
So at the end of all of this you have
- 3 master nodes, ensuring you always have a quorum if you lose one
- Some number of homogenous nodes in each tier, allowing for your configured data replication within the tier. The number of replicas may change as you migrate between tiers.
- Some number of client nodes
This is enough for most people, and is flexible in terms of adding more machines when needed.
If you use AWS to host Elasticsearch and want to go further, you can ensure that your system is available even if an Availability Zone goes down.
Install the cloud-aws Elasticsearch plugin, which has since been renamed to discovery-ec2, and set cloud.node.auto_attributes: true and cluster.routing.allocation.awareness.attributes: aws_availability_zone.
What this does is set a new node attribute, which you could have defined yourself like you did the tier above, based on the Availability Zone the instance is launched in. The routing awareness tells Elasticsearch to avoid putting the primary and replica on nodes with the same setting (node.aws_availability_zone) in addition to the default behavior of avoiding primary and replica on the same hostname. Without this plugin, or outside of EC2, you could manually set a node attribute with the a blade chassis, rack, or row identifier to get a similar spread of data around your datacenter.
Here’s a diagram of what this whole setup could look like, assuming you need want to use 3 AWS Availability Zones - A, B, and C and survive one, maybe two Availability Zone outages.
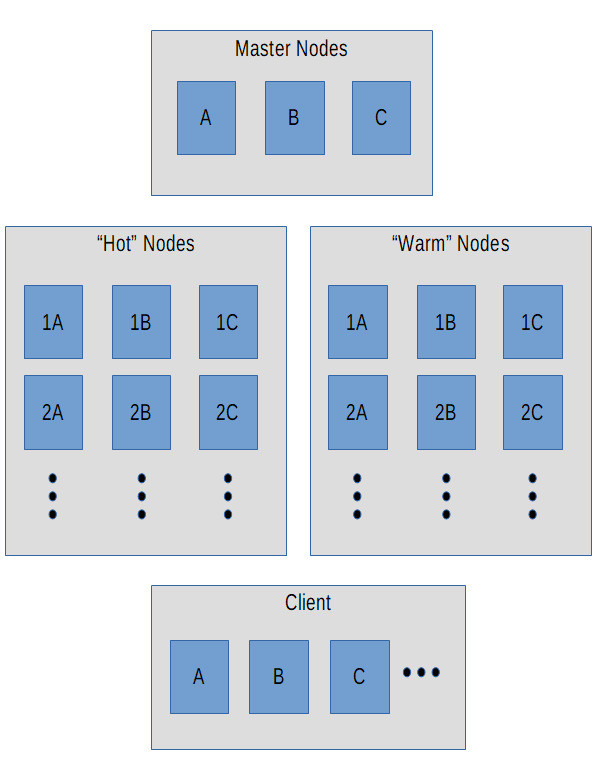
Why is this arranged like this?
You can lose a single Availability Zone and still have a quorum of masters, a primary shard, and a replica shard for each index.
If you lose a second Availability Zone, you still have a full copy of your data without needing to restore from backup. You no longer have a quorum in your masters though, so you would either need to quickly make one, or toggle node.master: true on one of your nodes to keep running.
A single AZ outage is a newsworthy event for the Internet, as many popular services fail. Why plan for two? Extra availability for your customers, as well as the ability to claim a EC2 SLA service credit for more than one AZ being unavailable.
Lose all 3? Well, there’s always backups. Make sure you’ve configured and tested snapshot and restore.